Consider Q2 in the Exercise Sheet 5 (Hypothesis Testing). A random sample \(X_1,\dots,X_n\) is drawn from a Pareto distribution with pdf \[
f(x \mid \alpha,\nu) = \frac{\alpha\nu^\alpha}{x^{\alpha+1}} \quad \text{for } x > \nu, \ \alpha > 0, \ \nu > 0
\] The Pareto distribution is frequently used in economics to model income and wealth distributions, especially the upper tail–where a small fraction of the population holds a disproportionately large share of income or wealth. This fits the famous Pareto Principle or 80/20 rule.
The two parameters in the Pareto distribution:
\(\nu\) (scale parameter): the minimum possible income/wealth (i.e., the distribution starts at this value),
\(\alpha\) (shape parameter): controls the “fatness” of the tail, smaller \(\alpha\) means fatter tails and greater inequality. In wealth modelling, this is the so-called Pareto index.
An example from empirical literature (e.g. Atkinson and Piketty, 2007) suggests that \(\alpha\) for income in the U.S. top 1% is around 1.5-2.5, depending on the year and method, while \(\nu\) varies depending on the income bracket analyzed, typically $100k to $500k for high earners.
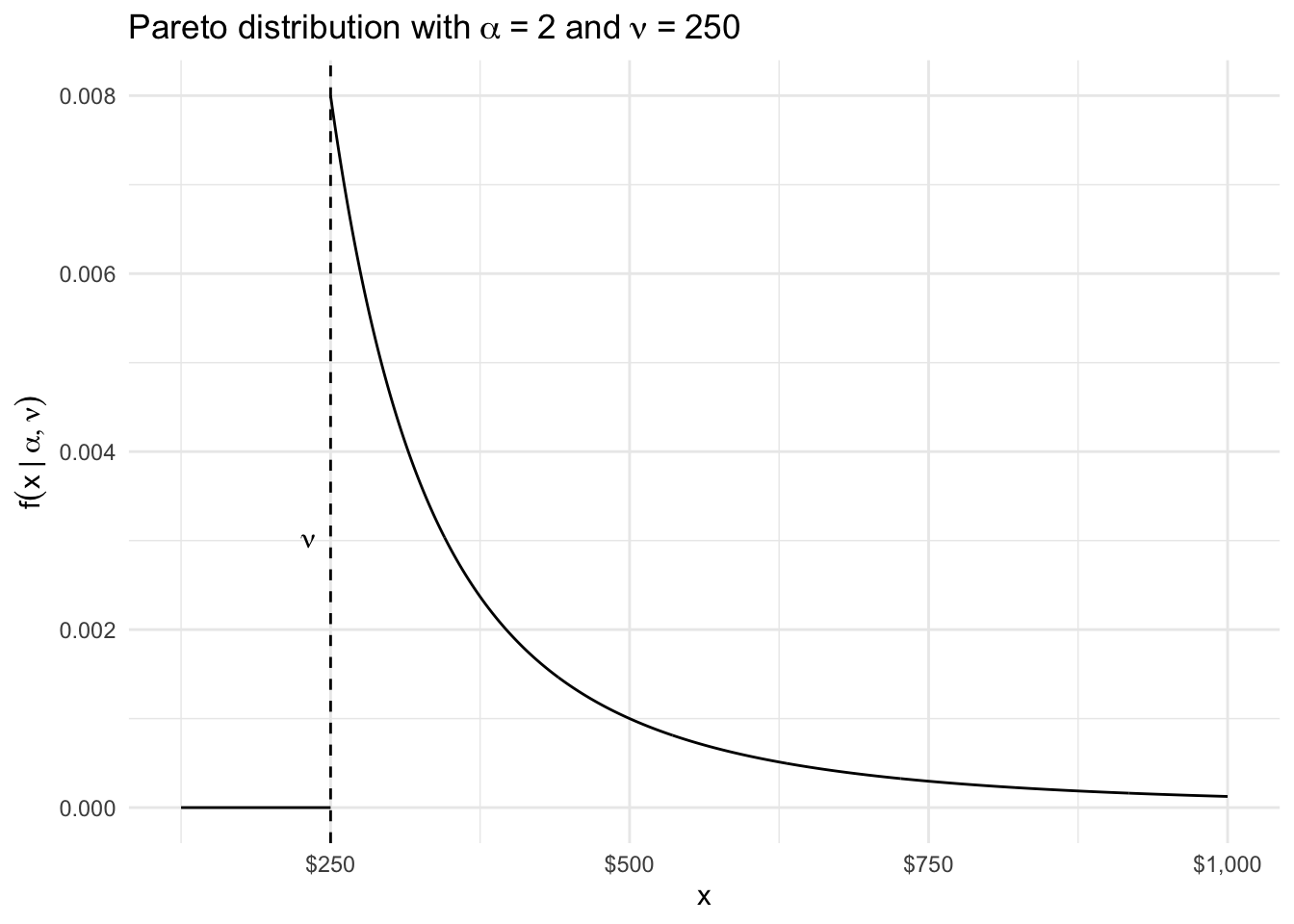
Here is what the pdf looks like:
Code
# True valuesalpha <-2# shape parameternu <-250# thousands of dollars, saytibble(x =seq(nu, nu*4, length.out =1000),f =case_when( x < alpha ~0,TRUE~ alpha * nu^alpha / x^(alpha +1))) |>ggplot(aes(x, f)) +geom_line() +geom_vline(xintercept = nu, linetype ="dashed") +annotate("segment", x = nu, xend = nu /2, y =0, yend =0) +annotate("text", x = nu, y =3e-3, label =expression(nu), hjust =2) +labs(title =expression("Pareto distribution with"~alpha~"="~2~"and"~nu~"="~250),x ="x",y =expression(f(x~"|"~alpha, nu)) ) +scale_x_continuous(labels = scales::dollar) +theme_minimal()
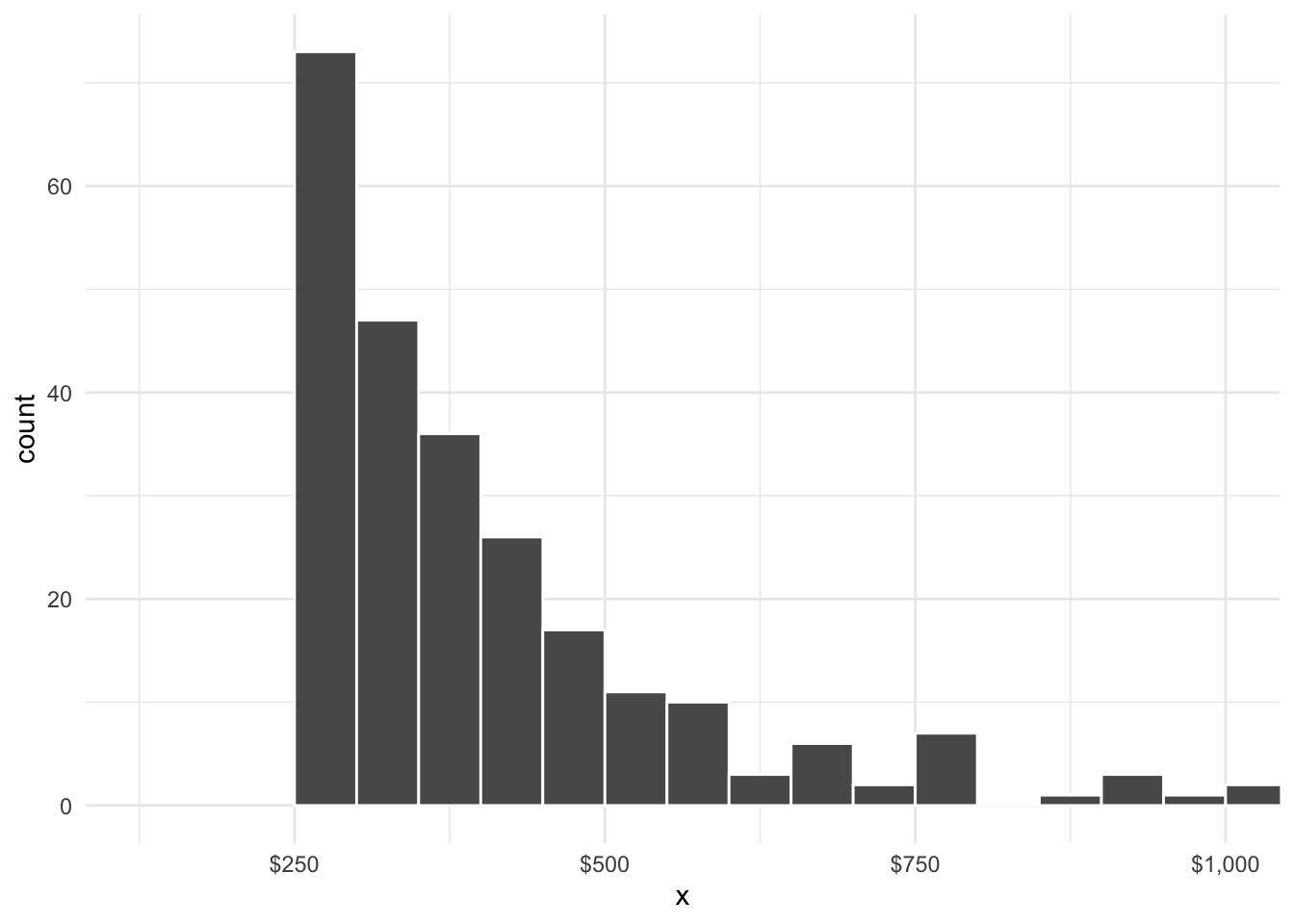
The following code generates a random sample of size \(n\) from the Pareto distribution with parameters \(\alpha = 2\) and \(\nu = 250\):
When we “draw” samples from a particular pdf, we expect the distribution of the sample (i.e., the histogram) to resemble the theoretical pdf. Do you see any resemblance? Looking ahead to parameter estimation, suppose the true value of \(\nu\) was not known. What value would you guess for \(\nu\) based on the data?
8.1 Paremeter estimation using MLE
In class, we solved for the MLE of \(\alpha\) and \(\nu\) in the usual way using derivatives and sketching the likelihood function. Recall that \[
\hat\alpha = \frac{n}{\sum_{i=1}^n \log(X_i/\hat\nu)} \quad \text{and} \quad
\hat\nu = \min(X_i).
\]
If we plug in the data to compute the MLE, we get:
We can also let the computer do the work for us using the nlminb() function in R. This function is a general-purpose optimization function that can be used to find the maximum likelihood estimates of parameters in a statistical model. What we need is to first code the likelihood function, and then use nlminb() to find the values of \(\alpha\) and \(\nu\) that maximize the likelihood function.
Code
# The pdf functionfx <-function(x, alpha, nu) { alpha * nu^alpha / x^(alpha +1)}fx(X[1:10], alpha, nu)
# The log-likelihood functionll <-function(theta) { alpha <- theta[1] nu <- theta[2]# Return really small value if support condition is violatedif (alpha <=0| nu <=0|any(X < nu)) return(-1e10)sum(log(fx(X, alpha, nu)))}ll(theta =c(2, 250))
[1] -1540.532
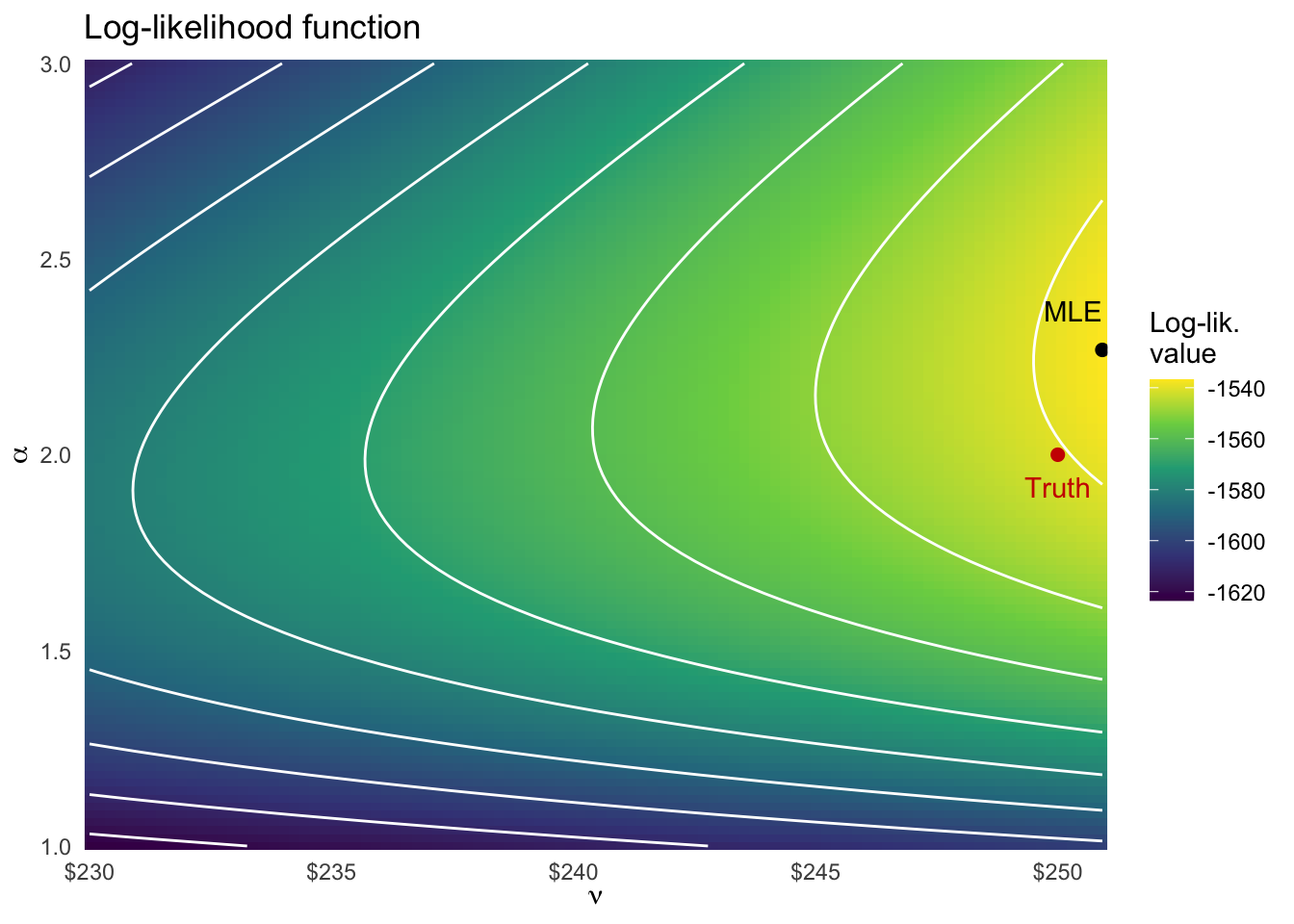
Here’s a plot of the 2-dimensional log-likelihood function based on the data:
Code
expand_grid(nu =seq(230, min(X), length.out =100),alpha =seq(1, 3, length.out =100)) |>mutate(ll = purrr::map2_dbl(alpha, nu, ~ll(c(.x, .y)))) |>filter(ll >-1e10) |>ggplot(aes(nu, alpha, z = ll)) +geom_raster(aes(fill = ll)) +geom_contour(color ="white") +scale_fill_viridis_c() +annotate("point", x = nu, y = alpha, color ="red3", size =2) +annotate("text", x = nu, y = alpha +0.1, label ="Truth", color ="red3", vjust =4) +annotate("point", x = nu_hat, y = alpha_hat, size =2) +annotate("text", x = nu_hat, y = alpha_hat +0.1, label ="MLE", vjust =0.5, hjust =1) +scale_x_continuous(labels = scales::dollar, expand =c(0, 0)) +scale_y_continuous(expand =c(0, 0)) +labs(title ="Log-likelihood function",x =expression(nu),y =expression(alpha),fill ="Log-lik.\nvalue" ) +theme_minimal()
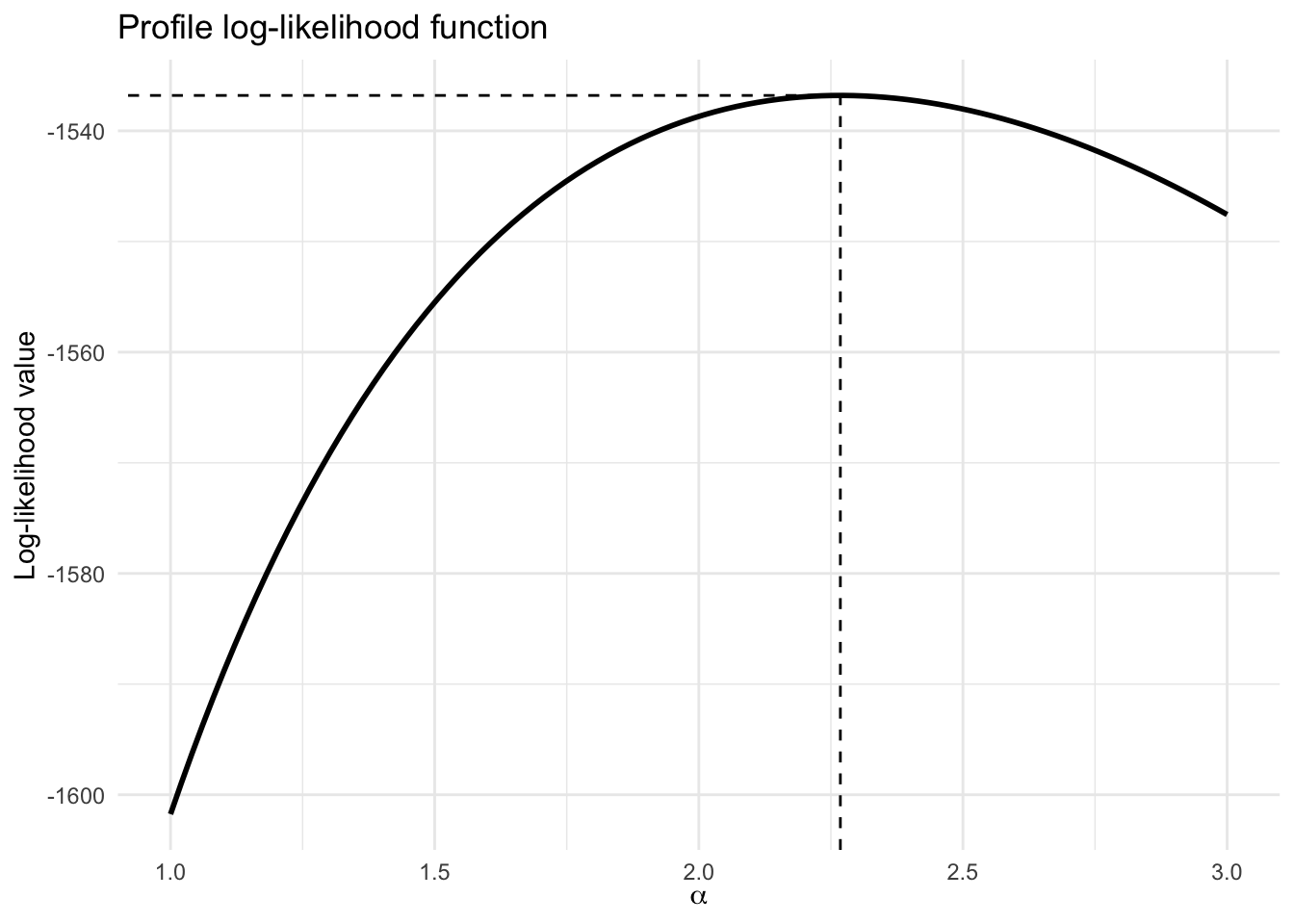
The profile log-likelihood function\[
f(\alpha) = \max_{\nu} \ell(\alpha, \nu) = \ell(\alpha \mid \hat\nu)
\] can be sketched as follows:
# Compare nlminb to direct calculations. They are identical!cat("nu_hat (calculation) =", nu_hat, "vs. nu_hat (MLE) =", res$par[2], "\nalpha_hat (calculation) =", alpha_hat, "vs. alpha_hat (MLE) =", res$par[1], "\n")
nu_hat (calculation) = 250.9195 vs. nu_hat (MLE) = 250.9195
alpha_hat (calculation) = 2.267916 vs. alpha_hat (MLE) = 2.267916
We can also check that the gradients are close to zero at the MLE. But only for the \(\alpha\) parameter, since the log-likelihood is not differentiable at \(\nu\)!
Code
# Gradient at MLEnumDeriv::grad(function(theta) -1*ll(theta), res$par)
[1] 1.654437e-06 1.937072e+12
The Hessian (observed Fisher information matrix) can also be obtained as follows: